Offchain Compute & Verification: Decentralized Databases for Smart Contracts

Smart contracts changed the game for trustless, programmable finance. They allowed us build lending protocols, decentralized exchanges, and token standards that operate without intermediaries. But there is a fundamental limitation to smart contracts that most developers run into sooner or later: they were never designed to handle data at scale.
The Storage Problem on the EVM
On the Ethereum Virtual Machine, every byte of data you store costs gas. Contract storage uses a key-value model with 256-bit slots, and writing to a new storage slot costs 20,000 gas. Modifying an existing slot costs 5,000 gas. At scale, storing even modest datasets entirely onchain becomes economically impractical. A simple lookup table with a few thousand entries can cost hundreds of dollars in gas fees to populate.
This is by design. Blockchains prioritize consensus and verification, not data warehousing. Every full node must replicate every piece of state, so bloating storage has a direct cost to the entire network. The result is that smart contracts can access only a very narrow window of data: wallet balances, the current transaction, and a handful of state variables. They cannot natively query historical transaction data, query data from other blockchains aggregate across multiple contracts, or access offchain datasets.
Oracles: The Current Patch
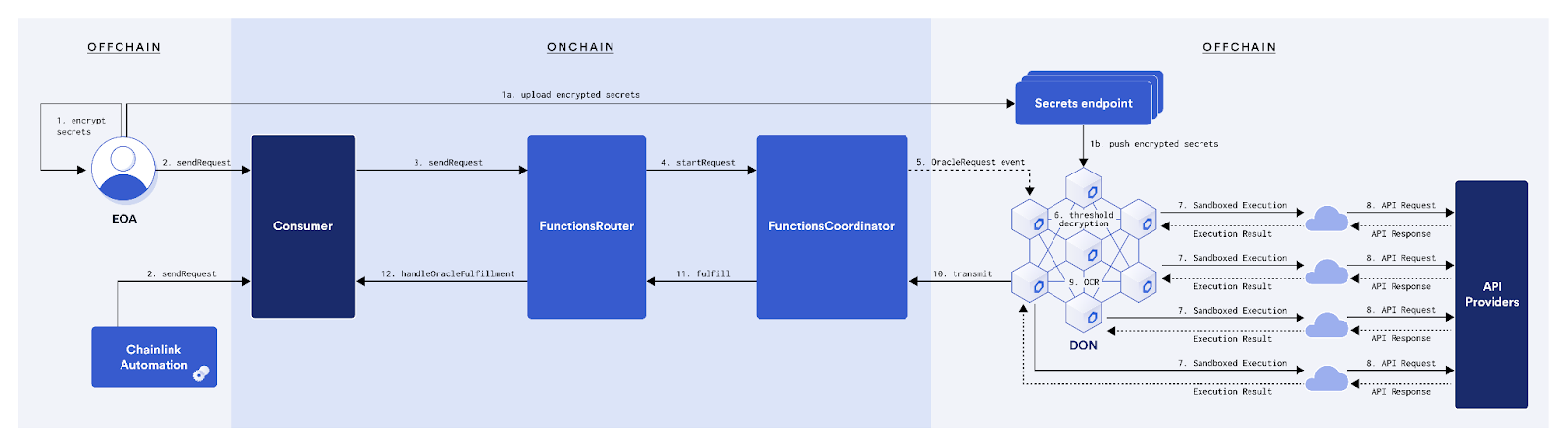
(Note source: Chainlink)
To bridge this gap, the industry adopted oracles. Oracle networks like Chainlink feed external data into smart contracts, and they have been instrumental in enabling DeFi. Price feeds, for instance, are the backbone of lending protocols and perpetual exchanges.
However, oracles come with meaningful limitations. First, they operate on a push model: someone has to decide what data to deliver and when. You cannot run an arbitrary query against historical blockchain data through a traditional oracle. Second, oracle updates introduce latency. Data is not available on-demand but on a schedule or when certain deviation thresholds are met. Third, and most importantly, the trust model of an oracle is fundamentally different from the trust model of the blockchain itself. You are trusting a committee of oracle nodes to deliver accurate data, which introduces a new trust assumption that did not exist in the onchain computation.
For simple, standardized data points like price feeds, this tradeoff is often acceptable. But for complex, application-specific queries, such as computing a borrower risk score across multiple protocols, aggregating trading activity for compliance, or determining airdrop eligibility based on historical behavior, oracles are not designed to handle the workload.
Why a Decentralized Database Layer Is the Missing Piece
What smart contracts actually need is not just isolated data points delivered on a schedule; they need a queryable data layer in which they can run computations over large datasets and receive verified results on-demand. In traditional software, this role is filled by databases; your application logic calls your database with a SQL query and gets back the exact answer it needs.
Blockchains have no equivalent. Archive nodes store raw historical data, but querying them is slow and requires custom indexing infrastructure, and the results carry no cryptographic guarantee that they have not been tampered with. Centralized indexing services like Etherscan or various subgraph providers can make the data queryable, but because there is no proof attached to the result, your smart contract cannot trust it.
This is the gap that a decentralized, verifiable database fills. Instead of storing all data onchain (which is prohibitively expensive) or relying on unverified offchain data (which breaks the trust model), a verifiable database stores data offchain, lets you query it with SQL, and generates a cryptographic proof that the query was executed correctly over data that has not been tampered with. Your smart contract can then verify this proof onchain before using the result.
How Space and Time Addresses This

Space and Time (SXT) is built specifically to serve as this data layer. SXT Chain is a decentralized layer 1 blockchain on which validators index data from major chains, including Ethereum, Bitcoin, ZKsync, Polygon, Sui, and Avalanche (among others), and ingest it into tamperproof tables. Validators reach BFT consensus on cryptographic commitments representing the current state of the data, which forms the root of trust for all subsequent queries.
When a developer queries SXT, the query is processed by a Prover node running Proof of SQL, a zero-knowledge coprocessor purpose-built for SQL operations. Unlike general-purpose zkVMs that treat computation as sequential instructions, Proof of SQL is designed from the ground up for data processing and parallelism. It can prove analytic queries of up to a million of rows in under a second using GPU acceleration, achieving latencies that are orders of magnitude faster than other ZK approaches.
The consequence is that smart contracts can now access historical, cross-chain, and offchain data as if it were natively available onchain. A DeFi lending protocol could compute a borrower's credit profile based on their entire transaction history across multiple chains. An insurance protocol could settle claims based on verified real-world data. Projects could allocate treasury funds based on provably accurate onchain activity metrics.
Moving Beyond the Data Wall
The limitations of smart contract storage and oracle-based data delivery are longstanding technical barriers. What is new is the availability of a practical solution that preserves the trustless properties that define smart contracts in the first place. A verifiable database layer does not ask you to trust a new set of intermediaries; instead, it extends the cryptographic guarantees of the blockchain to the data layer.
For developers building the next generation of onchain applications, this distinction matters. The applications that will define the next era of DeFi, whether is cross-chain derivatives, dynamic lending markets, or tokenized real-world assets, all require data processing at a scale that smart contracts alone cannot provide. The path forward is not to force more data onto the chain. It is to bring verifiable computation to the data and Space and Time solves this.
