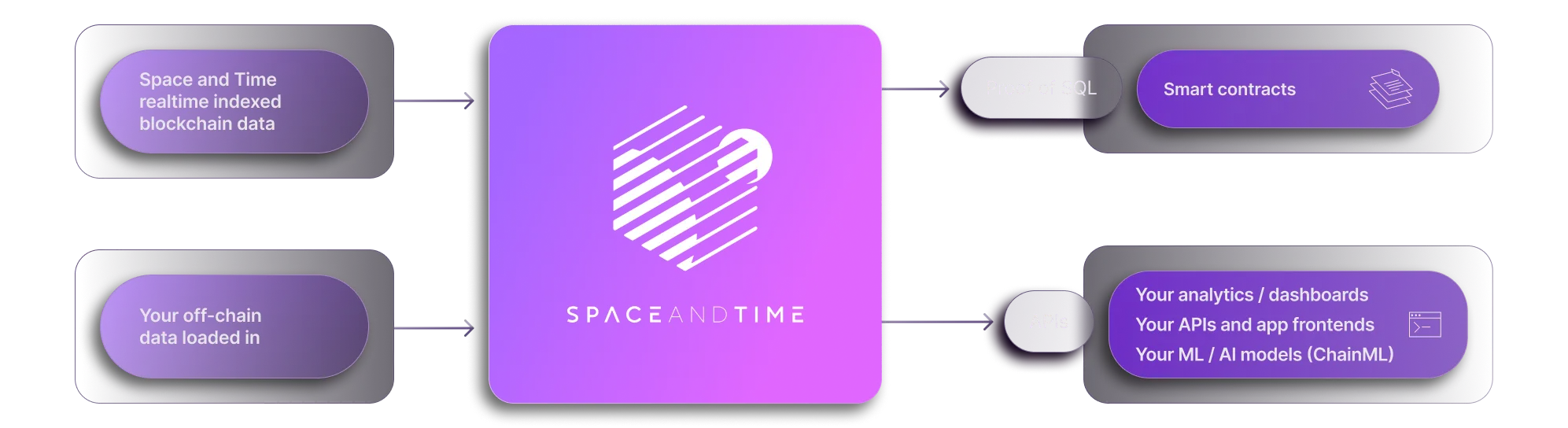
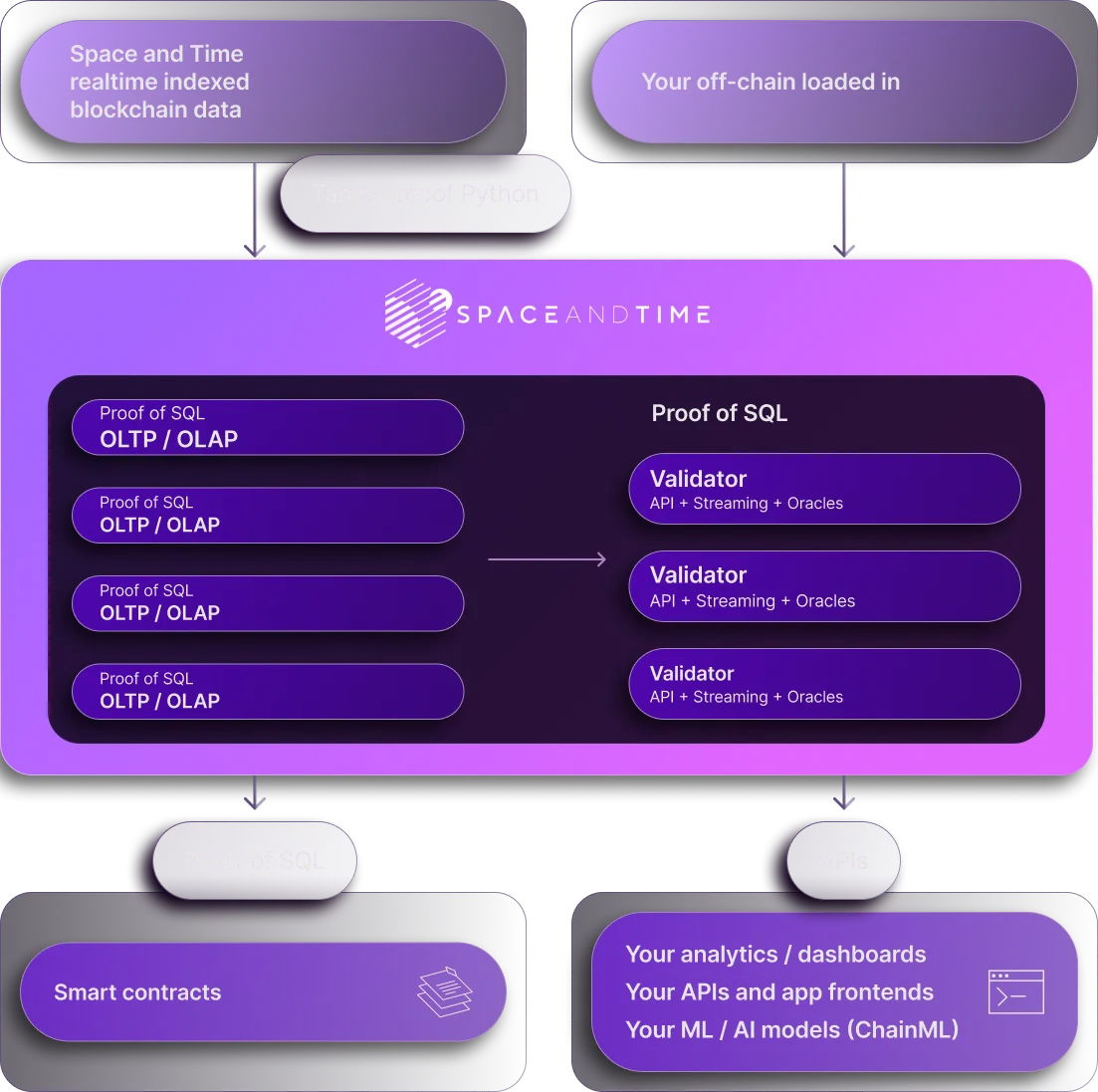
Verifiable Compute
Decentralized
Data Warehouse
AI-Powered SQL
Prompt-to-SQL + instant charts & dashboards.
Publish queries as REST APIs with a click.
Ingest new streams with a few keystrokes.
Verifiable Compute
Decentralized
Data Warehouse
Data Warehouse
Sub-Second ZK for SQL
SQL for smart contracts, with ZK proofs.
APIs to join onchain and offchain data.
Realtime blockchain data already loaded.